Introduction
In the landscape of computational biology, the ability to efficiently manage and execute complex analysis workflows is critical. Nextflow has emerged as a powerful tool for orchestrating such workflows, particularly in genomics. Its flexibility and scalability make it a go-to solution for researchers running intricate data pipelines. But how do you ensure these workflows run efficiently in a high-performance computing environment?
Enter the Gridware Cluster Scheduler, a robust and versatile workload manager built on the open-source Sun Grid Engine (SGE). By leveraging compatible interfaces with SGE, Gridware Cluster Scheduler offers seamless integration with tools like Nextflow. This combination optimizes resource allocation, enhances job scheduling capabilities, and ultimately accelerates data processing workflows.
In this blog post, we focus on the compelling synergy between Gridware Cluster Scheduler and Nextflow, showcasing how you can efficiently run Nextflow pipelines out-of-the-box on Gridware. To illustrate this, we will use an RNA Sequencing (RNA-Seq) pipeline as our example workflow. RNA-Seq is a widely-used method in genomics research, providing invaluable insights into gene expression.
Furthermore, we leverage Apptainer (formerly known as Singularity), a containerization solution that simplifies the deployment of complex workflows by ensuring consistent and portable environments. By integrating Apptainer, researchers can further streamline the execution of Nextflow pipelines across different computational setups without the hassle of dependency issues.
In the sections that follow, we’ll dive into the technical details of setting up and running an RNA-Seq pipeline on Gridware Cluster Scheduler using Nextflow and Apptainer. We will explore the setup and configuration processes, highlight the improvements in job submission and monitoring, and provide practical optimization tips. By the end of this post, you’ll see why Gridware Cluster Scheduler is your ideal companion for running high-efficiency Nextflow pipelines.
Stay tuned as we journey through this powerful integration, providing you with insights and practical guidance to enhance your computational biology workflows.
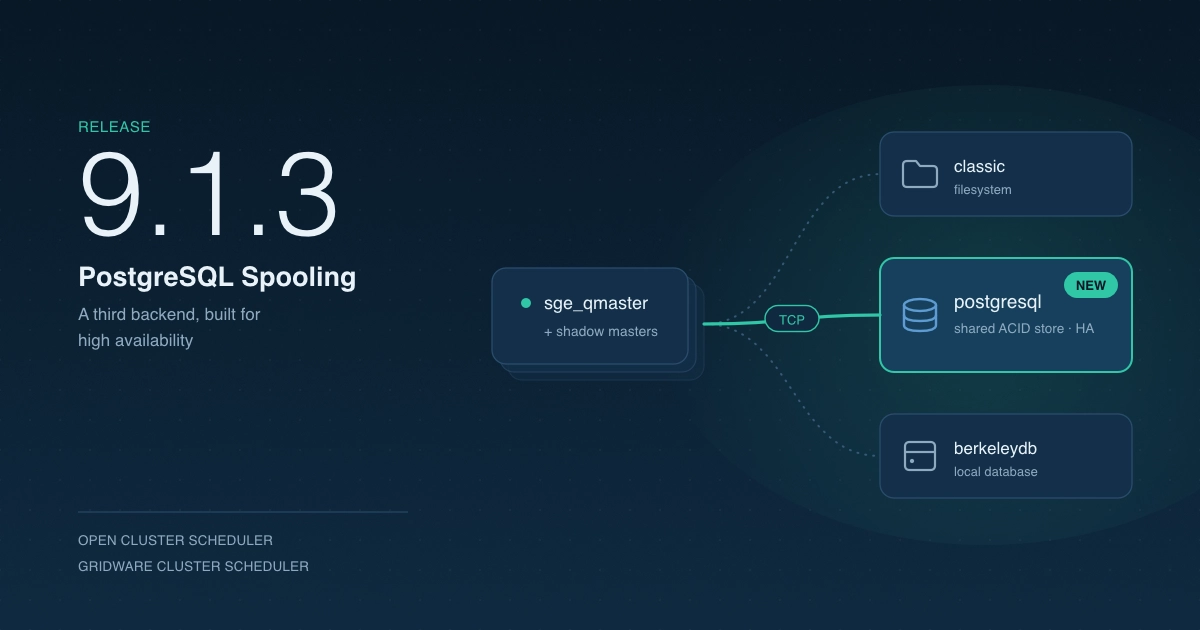
Introducing the new Gridware Cluster Scheduler
In the fast-evolving world of high-performance computing (HPC), having an efficient and reliable workload manager is paramount. The Gridware Cluster Scheduler is a workload manager tailored to meet these needs. Developed by the original creators of the Sun Grid Engine (SGE), Gridware Cluster Scheduler builds on a lineage of powerful, well-regarded scheduling systems.
At its core, Gridware Cluster Scheduler is built on the Open Cluster Scheduler project, a robust, open-source platform available on GitHub. This foundation ensures that the scheduler retains the compatibility, reliability and flexibility of SGE while introducing new enhancements aimed at modernizing and expanding its capabilities.
The integration and setup procedures discussed in this article apply universally to both the long-term supported Gridware Cluster Scheduler and its open-source counterpart, the Open Cluster Scheduler. For simplicity and ease of understanding, we will refer to both collectively as the Gridware Cluster Scheduler throughout the remainder of this discussion.
Key Capabilities and Features
1. Seamless Integration with SGE Interfaces
Gridware Cluster Scheduler fully supports SGE-compatible interfaces, ensuring smooth interoperability with existing software and workflow integrations. This commitment to interface compatibility means you can transition to Gridware without disrupting your current pipeline configurations. We actively collaborate with software vendors and integrators to maintain and enhance these interfaces.
2. Advanced Job Scheduling
The scheduler optimizes job execution by efficiently allocating resources and managing job queues. This ensures a balanced and high-throughput environment, reducing wait times and maximizing resource utilization. Examples include individual resource configurations for different task types of a parallel (MPI) job.
3. Scalability end Enterprise Environment Support
Designed to handle the demands of modern HPC environments, Gridware is highly scalable, making it suitable for both small clusters and extensive HPC systems. We continually enhance the product to support increasingly larger and more complex workloads. Examples include support for UNIX groups (primary and supplementary) based access control configuration in all objects.
4. User Experience Enhancements
We’ve introduced new interfaces and tools aimed at improving the end-user experience. One notable feature is the JSONL (JSON Lines) based accounting and reporting format, which offers extensible resource usage tracking. This can be customized for specific measurement needs, providing detailed insights into job performance and resource consumption.
5. GPU Integration
Gridware Cluster Scheduler supports advanced GPU workloads, seamlessly integrating GPU resources into the scheduling and accounting processes. This enables the efficient execution of GPU-accelerated tasks, essential for fields like machine learning and scientific simulations. Due to Gridware Cluster Scheduler’s ARM support the scheduler can optimize workload even on NVIDIA’s latest generation Grace Hopper platform.
6. Out-of-the-Box Container Support
Recognizing the growing importance of containerization in HPC, Gridware / Open Cluster Scheduler natively supports HPC container runtimes like Apptainer. This simplifies the deployment of containerized workflows, allowing for consistent and portable application environments across different computing systems.
At HPC Gridware, we are committed to delivering a robust and user-friendly scheduling system that meets the demands of contemporary HPC and AI workloads. If you are interested in learning more or have specific requirements, we encourage you to reach out to us directly.
With its blend of advanced features, seamless integration capabilities, and open-source foundation, Gridware Cluster Scheduler represents a proofed workload management system which is robust and extremely well integrated in existing solutions. In the following sections, we will show you how to set up and run a Nextflow RNA-Seq pipeline on this powerful scheduler, demonstrating its practical applications and advantages.
Nextflow: Simplifying Workflow Automation
Nextflow is a domain-specific language (DSL) and workflow management system that allows users to compose and execute computational pipelines in a portable and reproducible manner. Its core strengths lie in its flexibility and scalability, enabling the orchestration of tasks across a variety of computing environments, from local machines to large-scale HPC clusters and cloud platforms.
Key features of Nextflow include:
– Scalability and Portability: Nextflow workflows can seamlessly scale from a single laptop to thousands of nodes on a cluster or cloud infrastructure without changing the workflow definition.
– Reproducibility: By leveraging containers (e.g., Apptainer, Docker), Nextflow ensures that workflows are executed in consistent environments, mitigating issues related to dependency management and software versions.
– Modularity Workflows in Nextflow are composed of small, reusable modules, making them easy to maintain, debug, and extend.
– Event-driven Execution Nextflow uses an event-driven execution model, naturally supporting complex flow control, error handling, and retry mechanisms.
Integration with Gridware Cluster Scheduler
One of the standout features of Nextflow is its broad support for different job schedulers, including the “Sun Grid Engine” (SGE). Since the Gridware Cluster Scheduler retains full compatibility with SGE interfaces, integrating Nextflow with Gridware is straightforward and seamless.
Here’s how Nextflow’s support for SGE interfaces ensures seamless integration with the Gridware Cluster Scheduler:
1. Native Support for SGE Commands
Nextflow can natively execute SGE commands, which means that any pipeline designed to run on SGE can run without modification. This includes job submission, status monitoring, and resource allocation tasks.
2. Configuration Simplicity
Setting up Nextflow to work with Gridware Cluster Scheduler involves minimal configuration changes. Users can specify the Gridware („sge“-compatible) scheduler in their Nextflow configuration file, enabling Gridware’s powerful scheduling and resource management features.
3. Resource Management
Nextflow pipelines can leverage Gridware Cluster Scheduler’s advanced resource management capabilities, ensuring efficient use of computational resources. This is particularly beneficial for high-demand tasks such as RNA-Seq, where resource optimization is crucial.
4. Enhanced Monitoring and Reporting
With Gridware’s enhanced monitoring tools, users gain comprehensive insights into job performance and resource utilization. This integration enables detailed tracking of workflow progress and helps in diagnosing any issues that arise.
The synergy between Nextflow and Gridware Cluster Scheduler combines the best of both worlds: the unparalleled workflow automation capabilities of Nextflow and the robust job scheduling and resource management provided by Gridware. This powerful combination facilitates efficient, scalable, and reproducible workflows, empowering researchers to tackle complex computational challenges with ease.
In the next section, we will introduce Apptainer, another crucial component of this workflow setup, demonstrating how it complements Nextflow and Gridware Cluster Scheduler to further streamline computational pipelines.
Containerization with Apptainer
In the complex landscape of computational biology, reproducibility and portability are crucial. Ensuring that workflows run consistently across diverse computing environments is a significant challenge. This is where containerization steps in, and Apptainer (formerly known as Singularity) emerges as a powerful solution for delivery of secure application environments into HPC environments.
Introduction to Apptainer
Apptainer is an open-source container platform project in the High Performance Software Foundation (HPSF) which is hosted by the Linux Foundation. Apptainer is designed specifically for scientific and high-performance computing (HPC) use cases. Unlike traditional containerization tools like Docker and Podman, Apptainer is optimized for security and performance in multi-tenant computing cluster environments, making it ideal for use on shared HPC clusters and supercomputers. Apptainer does not require an external daemon hence it can just run just like a normal application inside Gridware and Open Cluster Scheduler.
Key features of Apptainer include:
– Security: Apptainer runs containers in user space and avoids requiring elevated privileges by using the user kernel namespace, which enhances security, especially in shared computing environments.
– Compatibility: It supports a wide range of applications and can run Docker containers natively, making it highly versatile.
– Performance: Apptainer is designed to run applications with minimal overhead, ensuring that the performance is closely aligned with native execution.
– Portability: Apptainer containers are highly portable, enabling users to create once and run anywhere without modifications.
How Apptainer Enhances Nextflow Pipelines
The integration of Apptainer with Nextflow and Gridware Cluster Scheduler creates a potent combination for running computational biology pipelines. Here’s how Apptainer enhances the deployment of Nextflow pipelines:
1. Reproducibility
Apptainer ensures that workflows are executed in consistent environments by encapsulating the full application stack—binaries, libraries, dependencies, and configurations—into a single portable and cryptographically verifiable image. This guarantees that workflows produce identical results regardless of where they are executed.
2. Portability Across HPC Systems
With Apptainer, Nextflow pipelines can run seamlessly across various HPC environments without the need for reconfiguration. This portability allows researchers to deploy their workflows on different clusters without worrying about underlying system dependencies.
3. Compatibility with Existing Solutions
Apptainer’s ability to import Docker images means that existing containerized workflows can be directly used, leveraging the extensive ecosystem of Docker containers. This compatibility simplifies the transition to Apptainer for users already familiar with Docker.
4. Improved Resource Utilization
By encapsulating dependencies, Apptainer containers help in avoiding conflicts and reducing dependency cycles. This leads to more efficient resource utilization, as each job runs in a clean, isolated environment tailored to its specific requirements.
5. Security in Multi-Tenant Environments
HPC clusters often operate in multi-tenant setups where security is a concern. Apptainer’s security model ensures that containers run as the user invoking them without requiring root permissions, minimizing security risks while allowing full access to the compute resources.
6. Ease of Deployment
Integrating Apptainer with Nextflow is straightforward. Nextflow can be configured to use Apptainer containers by specifying the container image in the workflow script. This seamless integration means that users can quickly containerize their workflows and take advantage of Apptainer’s benefits.
Practical Example
For an RNA-Seq pipeline, containerizing the workflow with Apptainer ensures that the complex bioinformatics tools and libraries are encapsulated within the container. This guarantees that every step of the RNA-Seq analysis runs in the same environment, whether on a researcher’s laptop or a large HPC system, ensuring consistent and reproducible results.
By integrating Apptainer with Nextflow and the Gridware Cluster Scheduler, researchers can achieve a streamlined, efficient, and secure workflow execution environment. This setup not only simplifies the management of computational pipelines but also enhances their reliability and performance.
In the next section, we’ll delve into the specifics of RNA-Seq workflows, providing a detailed introduction to their components and significance in genomics research.
Introduction to RNA-Seq Workflows
RNA sequencing (RNA-Seq) is a powerful and widely used technique in molecular biology that allows researchers to analyze the transcriptome of an organism—the complete set of RNA transcripts produced by the genome at a given time. By sequencing RNA molecules, scientists can gain insights into gene expression patterns, identify novel transcripts, and understand the functional elements of the genome. The process involves converting RNA into complementary DNA (cDNA), which is then sequenced using high-throughput sequencing technologies. The resulting data can be used to quantify gene expression, detect gene fusions, and identify post-transcriptional modifications. In this exercise, we used the rnaseq pipeline from nf-core.
nf-core/rnaseq is a bioinformatics pipeline specifically designed for the analysis of RNA sequencing data from organisms with a known reference genome and annotation. The pipeline accepts a samplesheet and FASTQ files as input, carrying out essential steps such as quality control (QC), trimming, and (pseudo-)alignment. It ultimately generates a gene expression matrix and a comprehensive QC report, providing a streamlined and standardized approach to RNA-Seq data analysis. For more information on rnaseq visit here.
Configuring the RNA-Seq Pipeline on Gridware Cluster Scheduler
Running an RNA-Seq pipeline effectively requires a well-configured setup. Here’s a step-by-step guide to setting up the RNA-Seq pipeline with Nextflow on the Gridware Cluster Scheduler. We’ll cover necessary configurations, prerequisites, and dependencies to ensure smooth operation.
1. Setup AWS EC2 Worker Instances
First, we’ll use AWS EC2 instances for our setup. We’ll choose the c5d.18xlarge instance type, which provides 72 cores and 144GB of memory. Ensure that you have at least 1.4TB of disk space in the (shared) folder which is used for running the nextflow pipeline.
2. Installation of Gridware Cluster Scheduler
We’ll assume that the Open Cluster Scheduler is already installed. If it’s not, you can download the free builds from here and follow the instructions in the installation guide to setup an Open Scheduler or Gridware Cluster Scheduler cluster. Contact us for more information.
3. Configuring Gridware Cluster Scheduler
1. Default Queue Configuration
Set 32 slots in the queue to be used (here default all.q) for the c5d.18xlarge instance.
qconf -mq all.q
# Set slots per host to 32
...
slots 322. Parallel Environment Configuration
Set up a parallel environment with $pe_slots allocation rule and a global limit of 9999 slots prevent potential limitations.
qconf -ap mype
# Inside the editor:
pe_name mype
slots 9999
…
allocation_rule $pe_slots
control_slaves FALSE
job_is_first_task TRUE
urgency_slots min
accounting_summary TRUE3. Global Configuration Setting
Optional: Enable submit library path when you want to get the LD_LIBRARY_PATH environment variable passed to the jobs. Per default it is filtered out.
qconf -mconf
…
qmaster_params ENABLE_SUBMIT_LIB_PATH=true4. Installing Nextflow on the Nodes
Install Nextflow by following these commands assuming Java is already installed on the nodes:
curl -s https://get.nextflow.io | bash
chmod +x nextflow
sudo mv nextflow /usr/local/bin
nextflow info5. Installing Apptainer on the Nodes
For installing Apptainer on the compute nodes, follow the instructions available at: Apptainer Installation Guide.
Rocky Linux, a community-driven project compatible with Red Hat Enterprise Linux, is the preferred OS for HPC setups and is fully supported by Apptainer, Gridware Cluster Scheduler, and Nextflow. It ensures seamless integration for high-performance computing environments.
Prebuilt packages are available for released versions of Apptainer on a variety of host operating systems.
Multiple architectures of RPMs are available for Red Hat Enterprise Linux and Fedora. Follow these steps on Red Hat Enterprise Linux derived systems to enable the EPEL repositories and install Apptainer:
1. Enable the EPEL repositories:
sudo dnf install -y epel-release2. To install a non-setuid installation of Apptainer:
sudo dnf install -y apptainer3. Or, for a setuid installation:
sudo dnf install -y apptainer-suid6. Handling Apptainer Cache
Depending on the capabilities of the underlying filesystem, Apptainer caching might need to be disabled due to how OCI caching and locking works in parallel executions . This is required for both apptainer pull and apptainer run commands. For apptainer run the Nextflow config can be used (see Prepare the Nextflow Configuration below) to pass the instructions. To disable the caching for both commands it is recommended to use the environment variable APPTAINER_DISABLE_CACHE=1 either at a system or at user level (by including in the launch.sh script).
7. Running the RNA-Seq Pipeline with Nextflow
With your environment set up, you can now proceed to develop and run your RNA-Seq pipeline with Nextflow on Gridware Cluster Scheduler, using Apptainer containers:
1. Prepare the Nextflow Configuration
Configure the pipeline to use sge and apptainer by setting the appropriate executor in your nextflow.config file:
profiles {
openclusterscheduler_profile {
process {
executor = 'sge'
queue = 'all.q'
memory = '24 GB'
cpus = 4
penv = 'mype'
clusterOptions = '-V'
}
aws {
client {
anonymous = true
}
}
params {
outdir = '/home/user/results'
}
apptainer {
pullTimeout = '80 min'
runOptions = '--disable-cache'
}
}
}We need to set aws.client.anonymous to prevent authentication issues when the pipeline downloads the required data from Amazons S3 buckets.
Note, that in our cases roughly 130GB of data is downloaded and at peak time 1.1TB are created on the cluster storage.
Following file is used as nf-params.json. It specifies the human genome reference build GRCh37 and the samplesheet to use.
{
"input": "https://raw.githubusercontent.com/nf-core/test-datasets/rnaseq/samplesheet/v3.10/samplesheet_full.csv",
"genome": "GRCh37",
"pseudo_aligner": "salmon",
"outdir": "/home/user/output"
}2. Run the Pipeline
We run nextflow itself as an Open Cluster Scheduler job rather than starting it on the command line.
For that we created a launch.sh script:
nextflow run nf-core/rnaseq -r 3.14.0 -name clusterscheduler_rnaseq_job_$JOB_ID -profile openclusterscheduler_profile,apptainer -c nextflow.config -params-file nf-params.jsonWe put the unique job into the name to have a unique name and alignment of the nextflow run job to the workload manager’s job id.
In order to start the workflow we run:
qsub -V ./launch.shNote, that -V is required in our environment as it submits all environment variables along with the job so that Open Cluster Scheduler can be used by nextflow to submit the jobs of the workflow. 276 jobs are created with a total runtime duration in our case of 14h 38min using 369.4 CPU hours.
Following these steps will set up and configure your RNA-Seq pipeline efficiently on Gridware Cluster Scheduler, leveraging Nextflow and Apptainer to ensure reproducibility, portability, and optimal resource utilization.
Monitoring the Workflow with GCS
A crucial aspect of running complex computational workflows is ensuring efficient job submission and comprehensive monitoring. The Gridware Cluster Scheduler (GCS) offers a suite of tools to streamline job submission and provide detailed tracking and performance metrics. Let’s explore the tools available and the enhancements that make GCS particularly powerful when using Nextflow.
Job Monitoring with GCS
To monitor active jobs of the workflow in the system, including both pending and running jobs, qstat is used. This command provides a real-time view of job statuses and resource allocation by job in terms of CPU, memory, and io usage.
Once a job is completed, `qacct` allows users to view detailed statistics about finished jobs. This includes resource usage, job duration, and exit status, providing comprehensive insights into job performance.
Enhanced Monitoring and Performance Tracking Features
The Gridware Cluster Scheduler introduces several enhancements to traditional monitoring and performance tracking known by SGE, making it easier to manage and analyze job data.
JSONL Accounting Records with qacct
One of the new enhancements is the ability for qacct to write accounting records in JSONL (JSON Lines) format. This format is highly efficient to process, as each job’s accounting data is represented as a single line of JSON.
The advantage of JSONL is its speed and compatibility with standard processing tools like jq, which allows for easy processing analysis of the data.
Moreover, the JSONL format is extensible. Administrators can add custom resource usage values via epilog scripts, which can then be included in the JSONL records. This flexibility enhances the ability to tailor the accounting process to specific needs and objectives.
Command Line Transparency
qacct in Gridware Cluster Scheduler now includes the submit command line in its accounting records. This new feature in the open-source version provides insights into the exact command used for submission, adding a layer of transparency. For users employing Nextflow, this means you can see precisely what Nextflow submitted to the workload manager, aiding in debugging and optimization.
Enhanced qstat
qstat has also been enhanced to show the full submission command line alongside the actual submission parameters applied. This feature provides a clear view of what Nextflow submits to the system, offering administrators greater transparency and control over job submissions.
This detailed view helps not only in monitoring active jobs but also in understanding and troubleshooting the submission process. Administrators can quickly identify and address any discrepancies or issues, ensuring smooth operations.
Conclusion
The Gridware Cluster Scheduler enhances the job submission and monitoring ecosystem by offering advanced features like JSONL accounting records, detailed command line transparency, and real-time job monitoring. These improvements are particularly beneficial when running complex workflows with Nextflow, providing deeper insights and more control over the computational environment. With these tools, researchers and administrators can ensure efficient resource utilization, streamline pipeline management, and achieve higher overall productivity.
RNA-Seq Pipeline Summary
Upon the completion of all pipeline jobs, Nextflow generates several detailed reports, which provide an in-depth overview of the entire workflow’s performance, including the Execution Report, which is a nicely formatted interactive html page which summarizes the execution details, including successful and failed tasks.
Conclusion
This case study highlights the effective integration of Nextflow with the Gridware Cluster Scheduler, demonstrating how this synergistic combination enhances the execution of complex RNA-Seq pipelines. Leveraging Nextflow’s workflow automation capabilities along with Gridware’s advanced job scheduling and resource management features results in significant performance gains and resource optimization.
The added integration of Apptainer ensures reproducibility and portability, providing a consistent execution environment across different computational setups. With these tools, researchers can achieve efficient, scalable, and reproducible workflows, addressing the complexities of computational biology with ease.
For more information, resources, and support, please visit our HPC Gridware, Nextflow, and CIQ websites. Join us in enhancing your computational biology workflows with robust, high-performance solutions.
Appendix
Open Cluster Scheduler: https://github.com/hpc-gridware/clusterscheduler/
Gridware Cluster Scheduler: https://hpc-gridware.com/gridware-cluster-scheduler/
Nextflow: https://www.nextflow.io/
Seqera: https://seqera.io/nextflow/
Apptainer: https://apptainer.org/
CiQ: https://ciq.com/products/apptainer/
RNASeq Configuration: https://nf-co.re/rnaseq/
RNA-Seq Wikipedia: https://en.wikipedia.org/wiki/RNA-Seq
Authors
Daniel Gruber, Chief Solutions Officer and Co-Founder of HPC Gridware GmbH
Rob Lalonde, Chief of Commercial Partnerships, Seqera Labs
Gregory M. Kurtzer, CEO and Founder of CIQ
Rob Syme, Scientific Support Lead at Seqera Labs